网络爬虫是什么?
本节我们先讲一下网络爬虫的概念,再讲一下网络爬虫的分类,期间会插入我个人的一些见解。
对于我们来说,爬虫需要我们自己写,可以下载的我们眼里最有价值的数据。
通常我们会把收集到的数据进行数据分析:
获取数据背后的结论(需要一些心理学知识才能推出来),还真须有大量随机的数据;而且爬取的数据要尽量随机、大规模,这样能够排除一切主观的干扰因素。
如果爬虫技术特别 NB,也可以直接去销售数据:
1) http://chinadatatrading.com/ 是销售数据的平台之一。
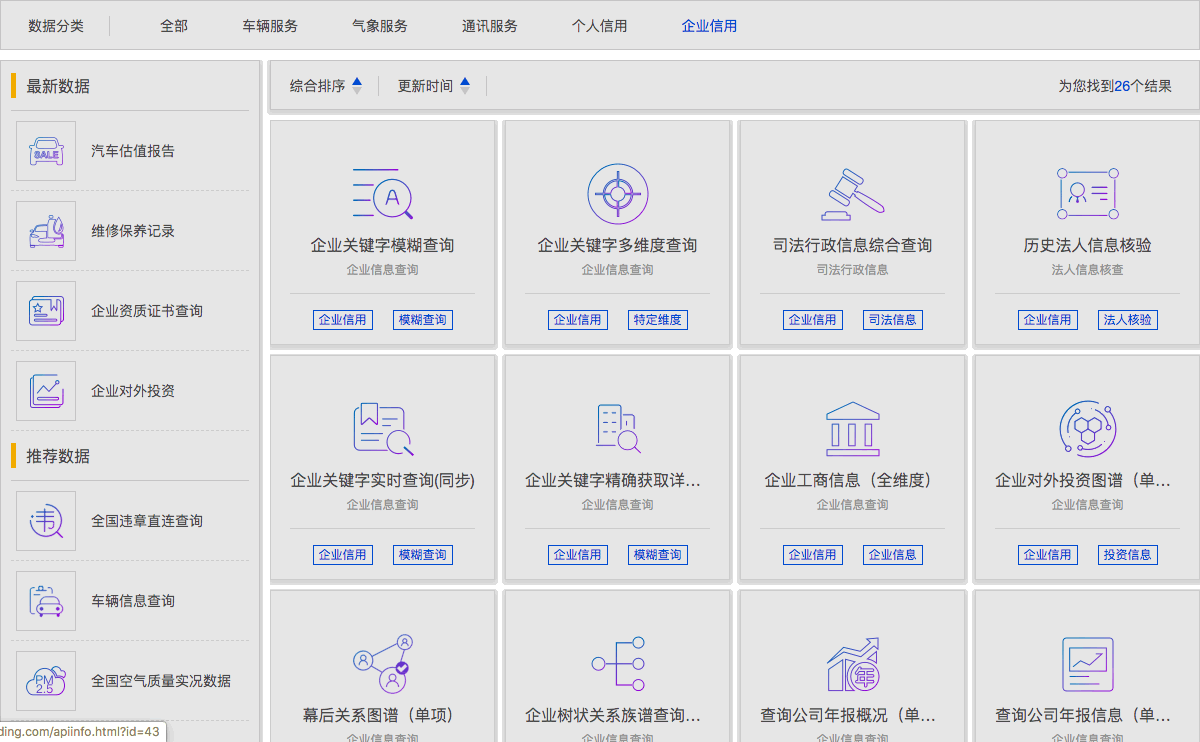
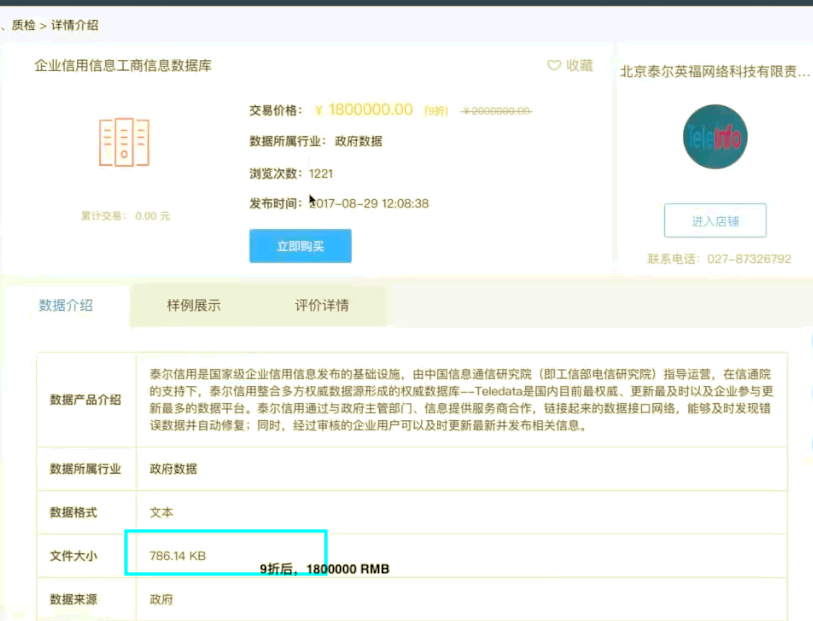
800KB 的数据(就是用硬盘下载也能1秒搞定),打 9 折后,180,0000 元。
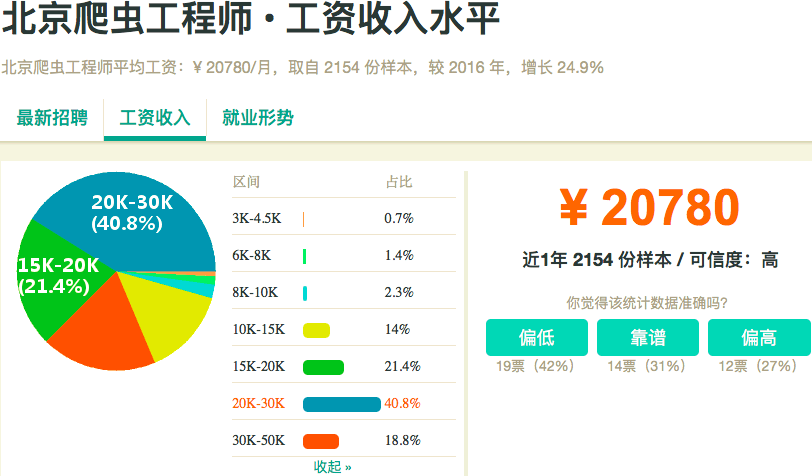
2) 靠谱一点的,还可以爬虫工程师的工资:
如果您喜欢编程这真是太好啦,不是所有的爱好都有一个副作用是给您赚钱的。
网赚这类基本上都是信息不对称,所以先从赚信息差入手,辅以赚认知差,长期储备赚技术差。
举个例子,美国现任总统特朗普喜欢发推特(推特同中国的微博,特朗普号称是“推特治国”),推文大概在小学水平:
美国大多数政客也是如此,这可不是政客越来越没文化,越来越随意 —— 恰恰相反,政客演讲现在是越来越不敢随意,TA们的用词和节奏都是经过精心计算的 —— 只有这样,TA们才能更好地争取选民。
譬如,不要问你的国家能为你做些什么,要问你能为你的国家做些什么,这句话的节奏是 ABBA。
这就是一个信息差呢,国内就有人实时翻译(爬虫技术)了特朗普的推文,微博粉丝暴涨 500 万。
如果您还能根据局势分析特朗普说的话,还可以继续赚技术差:

有没有感受到,特朗普是说服力大师 ??
特朗普对群众说的话,就好像是出自一个模版(说服力法则之一):先同步再领导。
是先取得了感情同步,紧接着就领导读者往前走一步,占领道德制高点。
特朗普这个级别的说服力:是你们不但要喜欢我,而且还要不喜欢我的对手。
推特治国名不虚传,如果再把自己的这份分析分享出去,那不就是继续赚认知差吗~
我们学习的是聚焦型爬虫,聚焦型爬虫是啥,很厉害嘛?
聚焦型爬虫与通用型爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
我们还是先科普一下,爬虫分类以及各自的优势。
下面的内容,完全不需要看懂,第一节主要是介绍一下。我们的爬虫课时的学习路径分为俩阶段:
以百度为例,您在搜索的时候仔细看,会发现每个搜索结果下面都有一个百度快照。
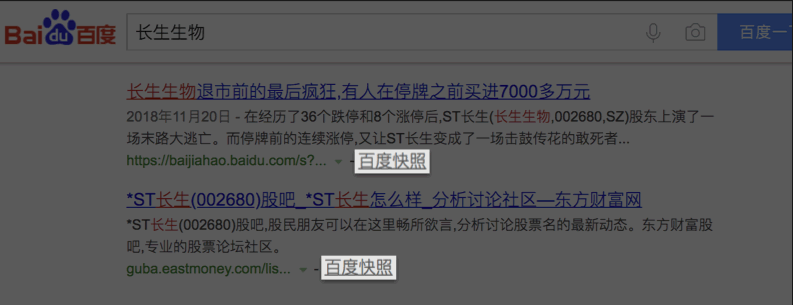
点击百度快照,就会发现网址的开头有 [baidu] 这个词,也就是说这个网页属于百度。

这些网页都被通用爬虫保存在本地的服务器里,通过浏览器我们能查询到所有被保存的网页。
那百度又是如何,下载到那么多的网页呢 ?
爬虫的原理是把每个网页看成图(离散数学、常用的数据结构之一)的一个节点,让网页和网页之间的超链接看做弧,整个互联网就是一个大大的有向图。
通用型爬虫也是一个程序,可以从任何一个网友出发,用图的遍历算法,自动的访问每一个网友并存储在服务器里。
考虑的方面:
这些,也会穿插在爬虫课时之间,能帮助您加深了解。
如果想缩短收录的时间,可以主动提交我们的网址给通用型爬虫(如百度的链接提交)。
注意了,以后我们说爬虫,默认是聚焦型爬虫。
爬虫的基本步骤 :
爬虫涉及的 Python 模块:
为了让小白了解收集到数据之后能干什么,爬虫课时将会涉及到:
网络爬虫是什么?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。对于我们来说,爬虫需要我们自己写,可以下载的我们眼里最有价值的数据。
通常我们会把收集到的数据进行数据分析:
-
如果我们想开淘宝零售店,可对淘宝这个市场并不了解,我们就可以爬取淘宝用户的行为数据,再考虑自己的定位在哪里。
数据表明:用户购买最多的商品是 100-200 RMB,最理想的定位应是 200 元以内却特别高端的物品。
-
如果我们想预测俩人是否会修成正果,我们可以把数据爬取了(如果是约会,全程对话录下来)预测。
数据表明:男性最后选择的总是外表好看的,这可能伤了您的心。
-
如果服务于企业(如腾讯),微信(有平台)对 90 后、80 后、70 后和 55 岁以上人群的使用习惯做了数据分析,结果发现:
- 00 后最喜欢使用的表情是捂脸哭,80 后最爱呲牙笑,70 后最爱捂嘴笑,55 岁以上人最爱大拇指点赞;
- 在阅读兴趣方面,90 后的阅读内容从三年前的娱乐八卦转向了生活情感类内容,55 岁以上人群从三年前的励志文化类内容转向了关注养生健康类内容,而 80 后的阅读偏好则仍然停留在关心国家大事上,你可以在每个阶段推送不同的且贴心的服务。
获取数据背后的结论(需要一些心理学知识才能推出来),还真须有大量随机的数据;而且爬取的数据要尽量随机、大规模,这样能够排除一切主观的干扰因素。
如果爬虫技术特别 NB,也可以直接去销售数据:
1) http://chinadatatrading.com/ 是销售数据的平台之一。
800KB 的数据(就是用硬盘下载也能1秒搞定),打 9 折后,180,0000 元。
2) 靠谱一点的,还可以爬虫工程师的工资:
如果您喜欢编程这真是太好啦,不是所有的爱好都有一个副作用是给您赚钱的。
关于赚钱
就拿赚钱来说,可以分为赚信息差、赚技术差、赚认知差。- 赚信息差:基于爬虫、主题聚合、社交网络分析等,成为信息大V,就是您拥有的小道消息比别人多。
- 赚技术差:历练技术,在人工智能、区块链、大数据、云原生等核心技术领域深耕,成为技术实力派,就是您的技术比别人强。
- 赚认知差:读书学习,例如教人写作、英语、编程培训等,就是您学得比别人快、比别人好。
网赚这类基本上都是信息不对称,所以先从赚信息差入手,辅以赚认知差,长期储备赚技术差。
举个例子,美国现任总统特朗普喜欢发推特(推特同中国的微博,特朗普号称是“推特治国”),推文大概在小学水平:
Donald J. Trump:Today we are going to win the great state of MICHIGAN and we are going to WIN back the White House! Thank you MI!....
您会发现这句话中除了密歇根这个名词稍微陌生,剩下的内容没有看不懂的。美国大多数政客也是如此,这可不是政客越来越没文化,越来越随意 —— 恰恰相反,政客演讲现在是越来越不敢随意,TA们的用词和节奏都是经过精心计算的 —— 只有这样,TA们才能更好地争取选民。
文章节奏,如格律、对仗、八股都是追求节奏的一种形式,西方的节奏又叫 “分形”,节奏形式同现在的流行音乐。
节奏是最简单也是最重要的信息技术。能让人听起来特别“顺”,有一种愉悦感,而后我们会把这种愉悦感投射到这句话的内容上去,我们会因此觉得这句话更有道理。譬如,不要问你的国家能为你做些什么,要问你能为你的国家做些什么,这句话的节奏是 ABBA。
这就是一个信息差呢,国内就有人实时翻译(爬虫技术)了特朗普的推文,微博粉丝暴涨 500 万。
如果您还能根据局势分析特朗普说的话,还可以继续赚技术差:
有没有感受到,特朗普是说服力大师 ??
特朗普对群众说的话,就好像是出自一个模版(说服力法则之一):先同步再领导。
是先取得了感情同步,紧接着就领导读者往前走一步,占领道德制高点。
特朗普这个级别的说服力:是你们不但要喜欢我,而且还要不喜欢我的对手。
推特治国名不虚传,如果再把自己的这份分析分享出去,那不就是继续赚认知差吗~
爬虫的分类
我们所熟悉的搜索引擎,如谷歌、百度、搜狗、必应、360,TA们的核心技术就是爬虫,属于通用型爬虫。我们学习的是聚焦型爬虫,聚焦型爬虫是啥,很厉害嘛?
聚焦型爬虫与通用型爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
我们还是先科普一下,爬虫分类以及各自的优势。
| 类型\相对特征 | 相对优势 | 相对劣势 |
|---|---|---|
| 通用爬虫(百度) | 能快速搜索到想要的内容 | 90% 的内容是用户不需要的 |
| 聚焦爬虫 | 爬取的内容十分精准 | 爬取的数据很固定 |
下面的内容,完全不需要看懂,第一节主要是介绍一下。我们的爬虫课时的学习路径分为俩阶段:
- 熟练掌握聚焦型爬虫
- 各种反爬攻略和实践
通用型爬虫
通用型爬虫也是我正在学习的内容,和聚焦型爬虫只是方向不一样而已。除非是去拥有搜索引擎的公司,很少有人会学通用型爬虫吧。以百度为例,您在搜索的时候仔细看,会发现每个搜索结果下面都有一个百度快照。
点击百度快照,就会发现网址的开头有 [baidu] 这个词,也就是说这个网页属于百度。
这些网页都被通用爬虫保存在本地的服务器里,通过浏览器我们能查询到所有被保存的网页。
那百度又是如何,下载到那么多的网页呢 ?
爬虫的原理是把每个网页看成图(离散数学、常用的数据结构之一)的一个节点,让网页和网页之间的超链接看做弧,整个互联网就是一个大大的有向图。
通用型爬虫也是一个程序,可以从任何一个网友出发,用图的遍历算法,自动的访问每一个网友并存储在服务器里。
考虑的方面:
- 遍历算法的选择,如何在尽量短的时间下载所有网页 ?
- 如何高效 URL 去重 ?
- 如何避免漏掉网页呢 ?
- JavaScript生成的网页,如何准确的提取出 URL 呢 ?
- 如何协调成千上万的服务器 ?
- 静态网页和动态网页需不需要分别处理 ?
这些,也会穿插在爬虫课时之间,能帮助您加深了解。
如果想缩短收录的时间,可以主动提交我们的网址给通用型爬虫(如百度的链接提交)。
聚焦型爬虫
通用型爬虫是搜索引擎的原身,也是一个程序;而聚焦型爬虫也是一个程序,主要是代替浏览器的程序根据我们设定的规则批量提取相关数据,而不需要我们去手动提取(通用型爬虫做不到这一点)。注意了,以后我们说爬虫,默认是聚焦型爬虫。
爬虫的基本步骤 :
- 获取数据:爬虫程序会根据提供的网址,向服务器发起请求,而后返回数据;
- 解析数据:爬虫程序把服务器返回的数据解析成我们能读懂的格式;
- 提取数据:爬虫程序再从中提取出需要的数据;
- 存储数据:爬虫程序把有用的数据保存起来,便于日后使用和分析。
爬虫涉及的 Python 模块:
| 模块 | 功能 |
|---|---|
| request | 获取网页信息,文本、音频、图片都可以的。 |
| Json | 解析 XHR 数据,也可以把字符串转为字典/列表 |
| bs4 | 解析网页源代码,提取需要的数据 |
| re | 功能同 bs4,不过功能更强且大多数编程语言都支持 |
| csv | 存储数据(文件形式) |
| selenium | 浏览器自动化 |
| openpyxl | 存储数据(excel文件形式) |
| gevent | 异步爬虫,建立爬虫军队加速爬取数据 |
| SMTP | 电子邮件 发送 |
| wxpy | 微信消息 处理 |
| pyautogui | 鼠标键盘 自动化 |
| MongoDB | 数据库 |
| Scrapy | 爬虫框架(代码直接套就好了,上面的都需要自己一个个实现) |
为了让小白了解收集到数据之后能干什么,爬虫课时将会涉及到:
- 人工智能:分词标注、相关词汇、图灵测试、文本转语音、人工智能的趋势;
- 黑客技术:DDos攻击、网络摄像头、Google Hacking;
- 算法:解迷宫、评估用户消费能力、人群聚类算法;
- 信息论:大数据思维、如何测量数据的相关性、如何选择数据;
- 自动化:微信自动化、浏览器自动化、发邮件自动化、制作动态二维码、电影下载自动化、鼠标自动化;
- 思想:使用创造性思维积累独特的数据、使用批判性思维切割数据辨识真伪、成长性思维主打自学(授人以鱼不如授人以渔)。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算