数据库设计的三大范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中,这种规则就是范式。范式是符合某一种级别的关系模式的集合。关系型数据库中的关系必须满足一定的要求,即满足不同的范式。
目前关系型数据库有六种范式,分别为:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、第四范式(4NF)、第五范式(5NF)和第六范式(6NF)。要求最低的范式是第一范式。第二范式在第一范式的基础上又进一步的添加了要求,其余范式依次类推。
一般说来,数据库只需满足第三范式就行了,而通常我们用的最多的就是第一范式、第二范式、第三范式,也就是接下来要讲的“三大范式”。
例如,客人住宿信息表 (姓名, 客人编号, 地址, 客房号, 客房描述, 客房类型, 客房状态, 床位数, 入住人数, 价格)。
其中,“地址”列还可以细分为国家、省、市、区等,甚至有的程序还把“姓名”列也拆分为“姓”和“名”等。如果业务需求中不需要拆分“地址”和“姓名”列,则该数据表符合第一范式,如果需要将“地址”列拆分,则下列写法符合第一范式:
客人住宿信息表(姓名, 客人编号, 国家, 省, 市, 区, 门牌号, 客房号, 客房描述, 客房类型, 客房状态, 床位数, 入住人数, 价格)。
客人住宿信息表中的数据主要用来描述客人住宿信息,所以该表主键为(客人编号,客房号):
其中,“➡”符号代表依赖。以上各列没有全部依赖于主键(客人编号,客房号),只是部分依赖于主键,不符合第二范式。
使用第二范式后,客人住宿信息表可以分解成以下两个表:
为了更好的理解第三范式,这里我们需要了解传递依赖。假设A、B 和 C 是关系 R 的三个属性,如果 A➡B 且 B➡C,则从这些函数依赖中,可以得出 A➡C。如上所述,依赖 A➡C 称之为传递依赖。
以第二范式中的客房信息表为例,初看该表时没有问题,满足第三范式,每列都和主键列“客房号”相关,再细看会发现:
为了满足第三范式,应该去掉“床位数”列,“价格”列和“客房类型”列,将客房信息表分解为如下两个表。
主键与外键在多表中的重复出现不属于数据冗余,非键字段的重复出现才是数据冗余。在客房表中客房状态存在冗余,需要进行规范化,规范化以后的表如下:
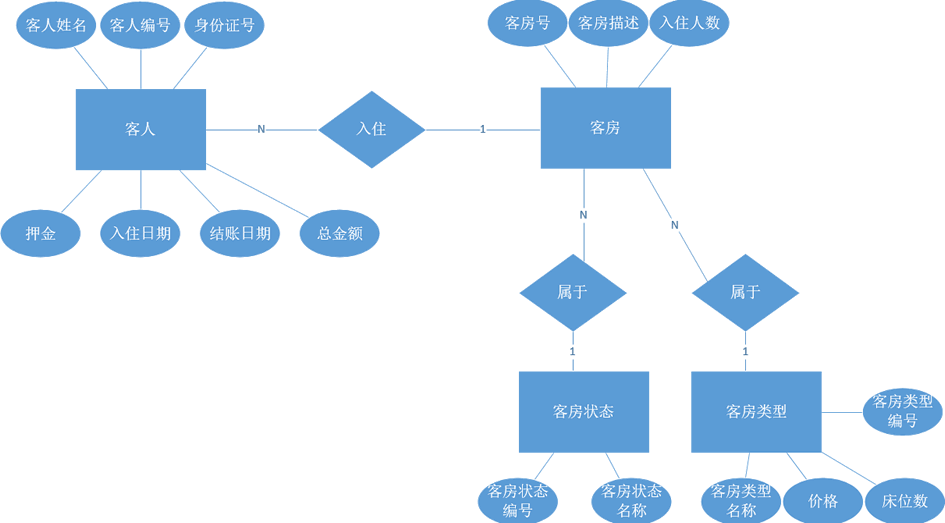
最后,满足三大范式的 E-R 图如下所示:
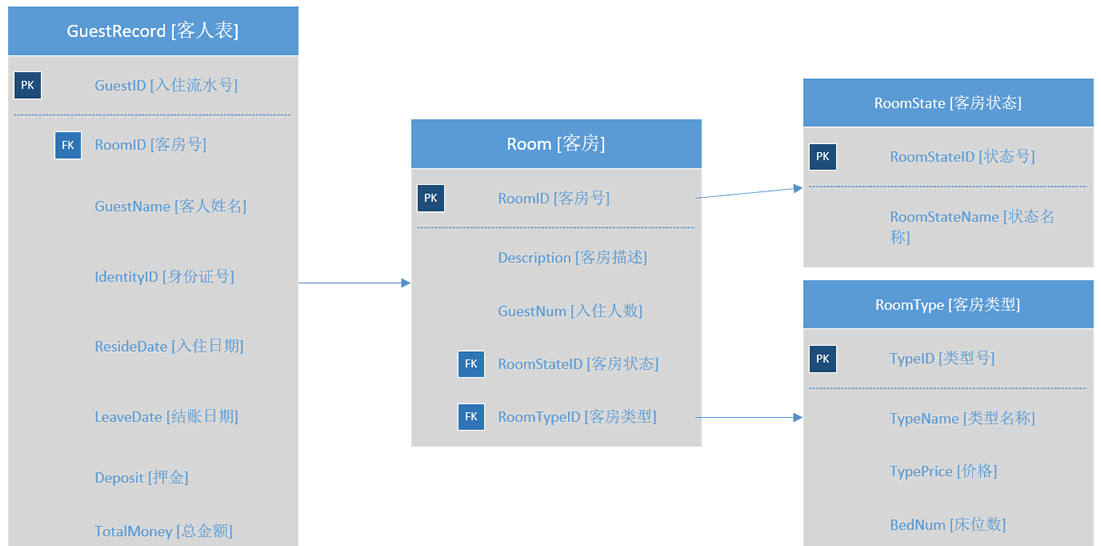
 满足三大范式的数据库模型图如下所示:
满足三大范式的数据库模型图如下所示:
我们需要知道对于项目的最终用户来说,用户关心的是方便,清晰的数据结果。所以在设计数据库时,设计人员和客户在数据库的设计规范化和性能之间会有一定的矛盾。
上面我们通过三大范式将客房表分解出两个表,为了满足客户的需求,最终可能需要通过三个或四个表之间的连接查询,来得到客户需要的数据结果,插入数据同样如此,对于客户输入的数据,我们需要分开插入到三个或四个不同的表中。
由此可以看出,为了满足三大范式,我们的数据操作性能会受到相应的影响。
所以,在实际的数据库设计中,既要考虑三大范式,避免数据的冗余和各种数据操作异常,又要考虑数据访问性能。为了减少表连接,提高数据库的访问性能,也可以允许适当的数据冗余列,这也许就是最合适的数据库设计方案。
比如,有一张存放商品的基本表,数据表中包括“单价”、“数量”“金额”等字段。“金额”这个字段就说明该表的设计不满足第三范式,因为“金额”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。
与第三范式中介绍的冗余相比,前面介绍的冗余属于低级冗余,我们反对低级冗余,但这里的冗余为高级冗余,目的是提高数据的处理速度,增加“金额”列后,可以提高查询统计的速度,这是以空间换取时间的做法。
缺点如下:
缺点如下:
目前关系型数据库有六种范式,分别为:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、第四范式(4NF)、第五范式(5NF)和第六范式(6NF)。要求最低的范式是第一范式。第二范式在第一范式的基础上又进一步的添加了要求,其余范式依次类推。
一般说来,数据库只需满足第三范式就行了,而通常我们用的最多的就是第一范式、第二范式、第三范式,也就是接下来要讲的“三大范式”。
1)第一范式
第一范式(1NF)用来确保每列的原子性,要求每列(或者每个属性值)都是不可再分的最小数据单元(也称为最小的原子单元)。例如,客人住宿信息表 (姓名, 客人编号, 地址, 客房号, 客房描述, 客房类型, 客房状态, 床位数, 入住人数, 价格)。
其中,“地址”列还可以细分为国家、省、市、区等,甚至有的程序还把“姓名”列也拆分为“姓”和“名”等。如果业务需求中不需要拆分“地址”和“姓名”列,则该数据表符合第一范式,如果需要将“地址”列拆分,则下列写法符合第一范式:
客人住宿信息表(姓名, 客人编号, 国家, 省, 市, 区, 门牌号, 客房号, 客房描述, 客房类型, 客房状态, 床位数, 入住人数, 价格)。
2)第二范式
第二范式(2NF)在第一范式的基础上更进一层,要求表中的每列都和主键相关,即要求实体的唯一性。如果一个表满足第一范式,并且除了主键以外的其他列全部都依赖于该主键,那么该表满足第二范式。客人住宿信息表中的数据主要用来描述客人住宿信息,所以该表主键为(客人编号,客房号):
- “姓名”列、“地址”列➡“客人编号”列。
- “客房描述”列、 “客房类型”列、“客房状态”列、“床位数”列、“入住人数”列、“价格”列➡“客房号”列。
其中,“➡”符号代表依赖。以上各列没有全部依赖于主键(客人编号,客房号),只是部分依赖于主键,不符合第二范式。
使用第二范式后,客人住宿信息表可以分解成以下两个表:
- 客人信息表(客人编号,姓名,地址,客房号,入住时间,结账日期,押金,总金额),主键为“客人编号”列,其他列都全部依赖于主键列。
- 客房信息表(客房号,客房描述,客房类型,客房状态,床位数,入住人数,价格),主键为“客房号”列,其他列都全部依赖于主键列。
3)第三范式
第三范式(3NF)在第二范式的基础上更进一层,第三范式是确保每列都和主键列直接相关,而不是间接相关,即限制列的冗余性。如果一个关系满足第二范式,并且除了主键以外的其他列都依赖于主键列,列和列之间不存在相互依赖关系,则满足第三范式。为了更好的理解第三范式,这里我们需要了解传递依赖。假设A、B 和 C 是关系 R 的三个属性,如果 A➡B 且 B➡C,则从这些函数依赖中,可以得出 A➡C。如上所述,依赖 A➡C 称之为传递依赖。
以第二范式中的客房信息表为例,初看该表时没有问题,满足第三范式,每列都和主键列“客房号”相关,再细看会发现:
- "床位数” 列、“价格”列➡“客房类型”列。
- “客房类型”列➡“客房号”列。
- “床位数”列、“价格”列➡“客房号”列
为了满足第三范式,应该去掉“床位数”列,“价格”列和“客房类型”列,将客房信息表分解为如下两个表。
- 客房表(客房号,客房描述,客房类型编号,客房状态,入住人数)
- 客房类型表(客房类型编号,客房类型名称,床位数,价格)
主键与外键在多表中的重复出现不属于数据冗余,非键字段的重复出现才是数据冗余。在客房表中客房状态存在冗余,需要进行规范化,规范化以后的表如下:
- 客房表(客房号,客房描述,客房类型编号,客房状态编号,入住人数)。
- 客房状态表(客房状态编号,客房状态名称)
最后,满足三大范式的 E-R 图如下所示:
4)反范式化
不满足范式的数据库设计,就是反范式化。我们需要知道对于项目的最终用户来说,用户关心的是方便,清晰的数据结果。所以在设计数据库时,设计人员和客户在数据库的设计规范化和性能之间会有一定的矛盾。
上面我们通过三大范式将客房表分解出两个表,为了满足客户的需求,最终可能需要通过三个或四个表之间的连接查询,来得到客户需要的数据结果,插入数据同样如此,对于客户输入的数据,我们需要分开插入到三个或四个不同的表中。
由此可以看出,为了满足三大范式,我们的数据操作性能会受到相应的影响。
所以,在实际的数据库设计中,既要考虑三大范式,避免数据的冗余和各种数据操作异常,又要考虑数据访问性能。为了减少表连接,提高数据库的访问性能,也可以允许适当的数据冗余列,这也许就是最合适的数据库设计方案。
比如,有一张存放商品的基本表,数据表中包括“单价”、“数量”“金额”等字段。“金额”这个字段就说明该表的设计不满足第三范式,因为“金额”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。
与第三范式中介绍的冗余相比,前面介绍的冗余属于低级冗余,我们反对低级冗余,但这里的冗余为高级冗余,目的是提高数据的处理速度,增加“金额”列后,可以提高查询统计的速度,这是以空间换取时间的做法。
注意:不要轻易违反数据库设计的规范化原则,如果处理不好,可能会适得其反,使应用程序运行速度更慢。
优缺点
最后我们来总结一下范式化和反范式化的优缺点。1)范式化
优点如下:- 减少数据冗余
- 范式化后的表中只有很少的重复数据,更新时只需要更新较少的数据,所以范式化的更新操作比反范式化更快
- 范式化的表通常比反范式化更小
缺点如下:
- 范式化的表在查询时经常需要很多的关联,这回导致性能降低
- 增加了索引优化的难度
2)反范式化
优点如下:- 可以减少表的关联
- 可以更好的进行索引优化
缺点如下:
- 数据表存在数据冗余及数据维护异常
- 对数据的修改需要更多的成本
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算