操作系统的体系结构(单处理器、多处理器和集群)
前面章节中,我们从操作系统的运行过程、存储结构以及I\O结构介绍了典型计算机系统的通用结构。计算机系统可能通过许多不同途径来组成,这里根据采用的通用处理器数量来进行粗略分类。
所有这些专用处理器执行有限指令集,而并不执行用户进程。在有的环境下,它们由操作系统来管理,此时操作系统将要做的任务信息发给它们,并监控它们的状态。
例如,磁盘控制器的微处理器接收来自主 CPU 的一系列请求,并执行自己的磁盘队列和调度算法。这种安排使得主 CPU 不必再执行磁盘调度。PC 的键盘有一个微处理器来将击键转换为代码,并发送给 CPU。
在其他的环境下,专用处理器作为低层组件集成到硬件。操作系统不能与这些处理器通信,但是它们可以自主完成任务。专用处理器的使用十分常见,但是这并不能将一个单处理器系统变成多处理器系统。如果系统只有一个通用 CPU,那么就为单处理器系统。
多处理器系统有三个主要优点:
对于许多应用,增加计算机系统的可靠性是极其重要的。根据剩余有效硬件的级别按比例继续提供服务的能力称为适度退化(graceful degradation)。有的系统超过适度退化,称为容错(fault tolerant),因为它们能够容忍单个部件错误,并且仍然继续运行。
容错需要一定的机制来对故障进行检测、诊断和(如果可能)纠错。HP NonStop 系统(以前的 Tandem)通过使用重复的硬件和软件,来确保在有故障时也能继续工作。该系统具有多对 CPU,它们锁步工作。每对处理器都各自执行自己的指令,并比较结果。如果结果不一样,那么其中一个 CPU 出错,此时两个都停下。接着,停着的进程被转到另一对 CPU,刚才出错的指令重新开始执行。这种方法比较昂贵,因为它用到专用硬件和相当多的重复硬件。
现在所用的多处理器系统有两种类型。有的系统采用非对称处理(asymmetric multiprocessing),即每个处理器都有各自特定的任务。一个主处理器(boss processor)控制系统,其他处理器或者向主处理器要任务或做预先规定的任务。这种方案称为主从关系。主处理器调度从处理器,并安排工作。
最为常用的多处理器系统采用对称多处理(Symmetric Multiprocessing,SMP),每个处理器都参与完成操作系统的所有任务。SMP 表示所有处理器对等,处理器之间没有主从关系。图 1 显示了一个典型的 SMP 结构。注意,每个处理器都有自己的寄存器集,也有私有或本地缓存;不过,所有处理器都共享物理内存。
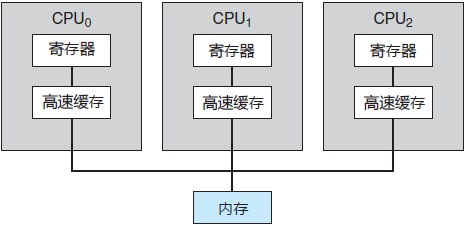
图 1 对称多处理的体系结构
SMP 的一个例子是 AIX,这是 IBM 设计的一种商用版 UNIX。每个 AIX 系统可以配有多个处理器。这种模型的优点是许多进程可以同时执行(如果有 N 个 CPU,那么可执行 N 个进程),而且并不会明显地影响性能。然而,应该仔细控制 I/O,确保数据到达适当处理器。
另外,由于各个 CPU 互相独立,一个可能空闲而另一个可能过载,导致效率低。这种低效是可以避免的,只要处理器共享一定的数据结构。这种形式的多处理器系统可动态共享进程和资源(包括内存),进而可降低处理器之间的差异。目前几乎所有现代操作系统,包括 Windows、Mac OSX 和 Linux 等,都支持 SMP。
对称与非对称处理的差异可能源于硬件或者软件。特定硬件可以区别多个处理器,软件也可编成选择一个处理器为主,其他的为从。例如,在同样的硬件上,SUN 操作系统 SunOS V4 只能提供非对称处理,而 SunOS V5(Solaris)则能提供对称处理。
多处理通过增加 CPU 来提高计算能力。如果 CPU 集成了内存控制器,那么增加 CPU 也能增大系统的访问内存。不论如何,多处理可使系统的内存访问模型,从均匀内存访问(Uniform Memory Access,UMA)改成非均勾内存访问(Non-Uniform Memory Access,NUMA)。对 UMA,CPU 访问 RAM 的所需时间相同;而对 NUMA,有的内存访问的所需时间更多,这会降低性能。操作系统通过资源管理可以改善 NUMA 的问题。
CPU 设计的最新趋势是,集成多个计算核(computing core)到单个芯片。这种多处理器系统为多核(multicore)。多核比多个单核更加高效,因为单片通信比多个芯片通信更快。再者,多核芯片的电源消耗比单核芯片低得多。
需要注意的是,多核系统为多处理器系统,但并不是所有多处理器系统都是多核的,。除非特别说明,本书在使用多核这一更为流行的术语时,并不包括一般的多处理器系统。
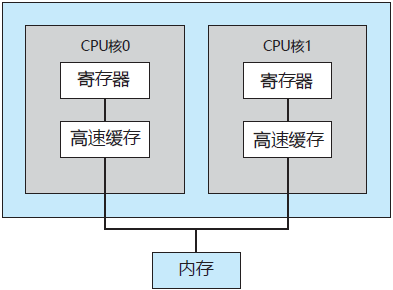
图 2 采用双核芯片设计
图 2 显示了一个双核设计。该设计的每个核都有自己的寄存器和本地缓存。其他的设计可能采用共享缓存,或混合采用本地缓存和共享缓存。如不考虑体系结构,如缓存、内存及总线竞争,这些多核 CPU 对操作系统而言就像是 N 个标准处理器。这一特点促使操作系统设计人员(及应用程序开发人员)充分利用这些处理核。
最后,最近开发的刀片服务器(blade server)将多处理器板、I/O 板和网络板全部置于同一机箱。它和传统多处理器系统的不同在于,每个刀片处理器可以独立启动,并且运行各自的操作系统。有些刀片服务器板也是多处理器的,从而模糊了计算机类型的划分。本质上,这些服务器由多个独立的多处理器系统组成。
应当注意的是,集群的定义尚未定型,许多商业软件对什么是集群系统有不同的定义,对什么形式的集群更好有不同的理解。较为公认的定义是,集群计算机共享存储,并且采用 LAN (Local Area Network,局域网)连接或更快的内部连接,如 InfiniBand。
集群通常用于提供高可用性(high availability)服务,这意味着即使集群中的一个或多个系统出错,仍可继续提供服务。一般来说,通过在系统中增加一定冗余,可获取高可用性。每个集群节点都执行集群软件层,以监视(通过局域网)一个或多个其他节点。如果被监视的机器失效,那么监视机器能够取代存储的拥有权,并重新启动在失效机器上运行的应用程序。应用程序的用户和客户只会感到短暂的服务中止。
集群可以是对称的,也可以是非对称的。对于非对称集群(asymmetric clustering),一台机器处于热备份模式(hot-standby mode),而另一台运行应用程序。热备份主机只监视活动服务器。如果活动服务器失效,那么热备份主机变成活动服务器。对于对称集群(symmetric clustering),两个或多个主机都运行应用程序,并互相监视。由于充分使用现有硬件,当有多个应用程序可供执行时,这种结构更为高效。
每个集群由通过网络相连的多个计算机系统组成,也可提供高性能计算(Mgh-performance computing)环境。每个集群的所有计算机可以并发执行一个应用程序,因此与单处理器和 SMP 系统相比,这样的系统能够提供更为强大的计算能力。
当然,这种应用程序应当专门编写,才能利用集群。这种技术称为并行计算(parallelization),即将一个程序分成多个部分,而每个部分可以并行运行在计算机或集群计算机的各个核上。通常,这类应用中的每个集群节点解决部分问题,而所有节点的计算结果合并在一起,以便形成最终解决方案。
其他形式的集群还有并行集群和 WAN(Wide-Area Network)集群。并行集群允许多个主机访问共享存储的同一数据。由于大多数操作系统并不支持多个主机同时访问数据,并行集群通常需要由专门软件或专门应用程序来完成。
例如,Oracle Real Application Cluster 就是一种可运行在并行集群上的、专用的 Oracle 数据库。每个机器都运行 Omcle,而且软件层跟踪共享磁盘的访问。每台机器对数据库内的所有数据都可以完全访问。为了提供这种共享访问,系统应当针对文件访问加以控制与加锁,以便确保没有冲突操作。有的集群技术包括了这种通常称为分布锁管理器(Distributed Lock Manager,DLM)的服务。
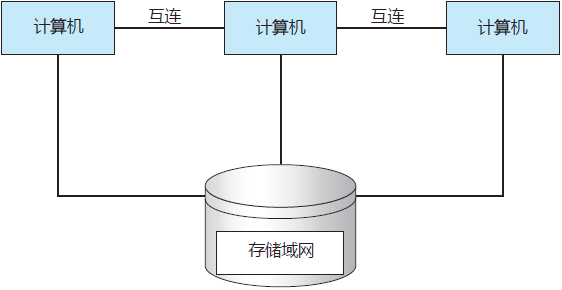
图 3 通用集群结构
集群技术发展迅速。有的集群产品支持数十个系统,而且集群节点也可分开数公里之 远。存储域网(Storage-Area Network,SAN)的出现也改进了集群性能,SAN 可让许多系统访问同一存储池。SAN 可以存储应用程序和数据,集群软件可将应用程序交给 SAN 的任何主机来执行。如果主机出错,那么其他主机可以接管过来。对于数据库集群,数十个主机可以共享同一数据库,从而大大提升了性能和可用性。图 3 显示了一个集群的通用结构。
单处理器系统
直到最近,大多数系统仍采用单处理器。单处理器系统只有一个主 CPU,以便执行一个通用指令集,该指令集包括执行用户进程的指令。几乎所有单处理器系统都带有其他专用处理器。它们或为特定设备的处理器,如磁盘、键盘、图形控制器;或为更通用的处理器,如在系统组件之间快速移动数据的 I/O 处理器。所有这些专用处理器执行有限指令集,而并不执行用户进程。在有的环境下,它们由操作系统来管理,此时操作系统将要做的任务信息发给它们,并监控它们的状态。
例如,磁盘控制器的微处理器接收来自主 CPU 的一系列请求,并执行自己的磁盘队列和调度算法。这种安排使得主 CPU 不必再执行磁盘调度。PC 的键盘有一个微处理器来将击键转换为代码,并发送给 CPU。
在其他的环境下,专用处理器作为低层组件集成到硬件。操作系统不能与这些处理器通信,但是它们可以自主完成任务。专用处理器的使用十分常见,但是这并不能将一个单处理器系统变成多处理器系统。如果系统只有一个通用 CPU,那么就为单处理器系统。
多处理器系统
近年来,多处理器系统(multiprocessing system,也称为并行系统(parallel system)或多核系统(multicore system))开始主导计算领域。这类系统有两个或多个紧密通信的 CPU,它们共享计算机总线,有时还共享时钟、内存和外设等。多处理器系统起初主要应用于服务器,后来也应用于桌面和笔记本系统。近来,多处理器也出现在移动设备上,如智能手机和平板电脑。多处理器系统有三个主要优点:
- 增加吞吐量:通过增加处理器数量,以期能在更短时间内完成更多工作。采用 N 个处理器的加速比不是 N,而是小于 N。当多个 CPU 协同完成同一任务时,为了让各部分能够正确执行,会有一定的额外开销。这些开销,加上竞争共享资源,会降低因增加了 CPU 的期望增益。这类似于 N 位程序员一起紧密工作,而不能完成 N 倍于单个程序员的工作量。
- 规模经济:多处理器系统的价格要低于相同功能的多个单处理器系统的价格,因为前者可以共享外设、大容量存储和电源供给。如果多个程序需要操作同一数据集,那么将这些数据放在同一磁盘并让多处理器共享,将比采用多个具有本地磁盘的计算机和多个数据副本更为节省。
- 增加可靠性:如果将功能分布在多个处理器上,那么单个处理器的失灵不会使得整个系统停止,而只会使它变慢。如果 10 个处理器中的 1 个出了故障,那么剩下的 9 个会分担起故障处理器的那部分工作。因此,整个系统只是比原来慢了 10%,而不是完全失败。
对于许多应用,增加计算机系统的可靠性是极其重要的。根据剩余有效硬件的级别按比例继续提供服务的能力称为适度退化(graceful degradation)。有的系统超过适度退化,称为容错(fault tolerant),因为它们能够容忍单个部件错误,并且仍然继续运行。
容错需要一定的机制来对故障进行检测、诊断和(如果可能)纠错。HP NonStop 系统(以前的 Tandem)通过使用重复的硬件和软件,来确保在有故障时也能继续工作。该系统具有多对 CPU,它们锁步工作。每对处理器都各自执行自己的指令,并比较结果。如果结果不一样,那么其中一个 CPU 出错,此时两个都停下。接着,停着的进程被转到另一对 CPU,刚才出错的指令重新开始执行。这种方法比较昂贵,因为它用到专用硬件和相当多的重复硬件。
现在所用的多处理器系统有两种类型。有的系统采用非对称处理(asymmetric multiprocessing),即每个处理器都有各自特定的任务。一个主处理器(boss processor)控制系统,其他处理器或者向主处理器要任务或做预先规定的任务。这种方案称为主从关系。主处理器调度从处理器,并安排工作。
最为常用的多处理器系统采用对称多处理(Symmetric Multiprocessing,SMP),每个处理器都参与完成操作系统的所有任务。SMP 表示所有处理器对等,处理器之间没有主从关系。图 1 显示了一个典型的 SMP 结构。注意,每个处理器都有自己的寄存器集,也有私有或本地缓存;不过,所有处理器都共享物理内存。
图 1 对称多处理的体系结构
SMP 的一个例子是 AIX,这是 IBM 设计的一种商用版 UNIX。每个 AIX 系统可以配有多个处理器。这种模型的优点是许多进程可以同时执行(如果有 N 个 CPU,那么可执行 N 个进程),而且并不会明显地影响性能。然而,应该仔细控制 I/O,确保数据到达适当处理器。
另外,由于各个 CPU 互相独立,一个可能空闲而另一个可能过载,导致效率低。这种低效是可以避免的,只要处理器共享一定的数据结构。这种形式的多处理器系统可动态共享进程和资源(包括内存),进而可降低处理器之间的差异。目前几乎所有现代操作系统,包括 Windows、Mac OSX 和 Linux 等,都支持 SMP。
对称与非对称处理的差异可能源于硬件或者软件。特定硬件可以区别多个处理器,软件也可编成选择一个处理器为主,其他的为从。例如,在同样的硬件上,SUN 操作系统 SunOS V4 只能提供非对称处理,而 SunOS V5(Solaris)则能提供对称处理。
多处理通过增加 CPU 来提高计算能力。如果 CPU 集成了内存控制器,那么增加 CPU 也能增大系统的访问内存。不论如何,多处理可使系统的内存访问模型,从均匀内存访问(Uniform Memory Access,UMA)改成非均勾内存访问(Non-Uniform Memory Access,NUMA)。对 UMA,CPU 访问 RAM 的所需时间相同;而对 NUMA,有的内存访问的所需时间更多,这会降低性能。操作系统通过资源管理可以改善 NUMA 的问题。
CPU 设计的最新趋势是,集成多个计算核(computing core)到单个芯片。这种多处理器系统为多核(multicore)。多核比多个单核更加高效,因为单片通信比多个芯片通信更快。再者,多核芯片的电源消耗比单核芯片低得多。
需要注意的是,多核系统为多处理器系统,但并不是所有多处理器系统都是多核的,。除非特别说明,本书在使用多核这一更为流行的术语时,并不包括一般的多处理器系统。
图 2 采用双核芯片设计
图 2 显示了一个双核设计。该设计的每个核都有自己的寄存器和本地缓存。其他的设计可能采用共享缓存,或混合采用本地缓存和共享缓存。如不考虑体系结构,如缓存、内存及总线竞争,这些多核 CPU 对操作系统而言就像是 N 个标准处理器。这一特点促使操作系统设计人员(及应用程序开发人员)充分利用这些处理核。
最后,最近开发的刀片服务器(blade server)将多处理器板、I/O 板和网络板全部置于同一机箱。它和传统多处理器系统的不同在于,每个刀片处理器可以独立启动,并且运行各自的操作系统。有些刀片服务器板也是多处理器的,从而模糊了计算机类型的划分。本质上,这些服务器由多个独立的多处理器系统组成。
集群系统
另一类型的多处理器系统是集群系统(clustered system),这种系统将多个 CPU 组合在一起。集群系统与刚刚所述的多处理器系统不同,它由两个或多个独立系统(或节点)组成。这样的系统称为松耦合的(loosely coupled)。每个节点可为单处理器系统或多核系统。应当注意的是,集群的定义尚未定型,许多商业软件对什么是集群系统有不同的定义,对什么形式的集群更好有不同的理解。较为公认的定义是,集群计算机共享存储,并且采用 LAN (Local Area Network,局域网)连接或更快的内部连接,如 InfiniBand。
集群通常用于提供高可用性(high availability)服务,这意味着即使集群中的一个或多个系统出错,仍可继续提供服务。一般来说,通过在系统中增加一定冗余,可获取高可用性。每个集群节点都执行集群软件层,以监视(通过局域网)一个或多个其他节点。如果被监视的机器失效,那么监视机器能够取代存储的拥有权,并重新启动在失效机器上运行的应用程序。应用程序的用户和客户只会感到短暂的服务中止。
集群可以是对称的,也可以是非对称的。对于非对称集群(asymmetric clustering),一台机器处于热备份模式(hot-standby mode),而另一台运行应用程序。热备份主机只监视活动服务器。如果活动服务器失效,那么热备份主机变成活动服务器。对于对称集群(symmetric clustering),两个或多个主机都运行应用程序,并互相监视。由于充分使用现有硬件,当有多个应用程序可供执行时,这种结构更为高效。
每个集群由通过网络相连的多个计算机系统组成,也可提供高性能计算(Mgh-performance computing)环境。每个集群的所有计算机可以并发执行一个应用程序,因此与单处理器和 SMP 系统相比,这样的系统能够提供更为强大的计算能力。
当然,这种应用程序应当专门编写,才能利用集群。这种技术称为并行计算(parallelization),即将一个程序分成多个部分,而每个部分可以并行运行在计算机或集群计算机的各个核上。通常,这类应用中的每个集群节点解决部分问题,而所有节点的计算结果合并在一起,以便形成最终解决方案。
其他形式的集群还有并行集群和 WAN(Wide-Area Network)集群。并行集群允许多个主机访问共享存储的同一数据。由于大多数操作系统并不支持多个主机同时访问数据,并行集群通常需要由专门软件或专门应用程序来完成。
例如,Oracle Real Application Cluster 就是一种可运行在并行集群上的、专用的 Oracle 数据库。每个机器都运行 Omcle,而且软件层跟踪共享磁盘的访问。每台机器对数据库内的所有数据都可以完全访问。为了提供这种共享访问,系统应当针对文件访问加以控制与加锁,以便确保没有冲突操作。有的集群技术包括了这种通常称为分布锁管理器(Distributed Lock Manager,DLM)的服务。
图 3 通用集群结构
集群技术发展迅速。有的集群产品支持数十个系统,而且集群节点也可分开数公里之 远。存储域网(Storage-Area Network,SAN)的出现也改进了集群性能,SAN 可让许多系统访问同一存储池。SAN 可以存储应用程序和数据,集群软件可将应用程序交给 SAN 的任何主机来执行。如果主机出错,那么其他主机可以接管过来。对于数据库集群,数十个主机可以共享同一数据库,从而大大提升了性能和可用性。图 3 显示了一个集群的通用结构。
Beowulf 集群
Beowulf 集群的设计用于解决高性能的计算任务。每个 Beowulf 集群由商用硬件(如个人计算机),通过筒单的 LAN 而连在一起。这种集群无需特定软件包,每个节点采用开源软件库来通信。因此每个 Beowulf 集群的构成方法有很多。通常,每个 Beowulf 计算 节点都运行 Linux 操作系统。由于并不要求专门硬件而只采用免费的开源软件,构成这种高性能计算的集群更为经济。实际上,有的 Beowulf 集群采用数百台遗弃的计算机,以便解决大运算量的科学计算问题。所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算