大数据流式计算框架汇总和对比
大数据计算引擎的发展经历了几个过程,从第 1 代的 MapReduce,到第 2 代基于有向无环图的 Tez,第 3 代基于内存计算的 Spark,再到第 4 代的 Flink。
Storm 是比较早的流式计算框架,后来又出现了 Spark Streaming 和 Trident,现在又出现了 Flink 这种优秀的实时计算框架,那么这几种计算框架到底有什么区别呢?下面我们来详细分析一下,如下表所示。
在这里对这几种框架进行对比。
官网中 Flink 和 Storm 的吞吐量对比如下图所示。
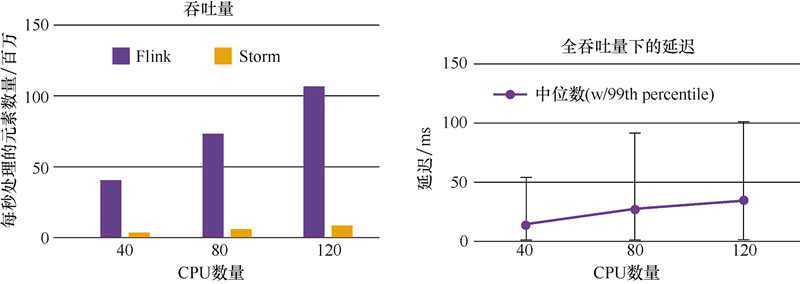
图3:Flink 和 Storm 的吞吐量对比
需要关注流数据是否需要进行状态管理,如果是,那么只能在 Trident、Spark Streaming 和 Flink 中选择一个。
需要考虑项目对 At-least-once(至少一次)或者 Exactly-once(仅一次)消息投递模式是否有特殊要求,如果必须要保证仅一次,也不能选择 Storm。
对于小型独立的项目,并且需要低延迟的场景,建议使用 Storm,这样比较简单。
如果你的项目已经使用了 Spark,并且秒级别的实时处理可以满足需求的话,建议使用 Spark Streaming。
要求消息投递语义为 Exactly-once;数据量较大,要求高吞吐低延迟;需要进行状态管理或窗口统计,这时建议使用 Flink。
Storm 是比较早的流式计算框架,后来又出现了 Spark Streaming 和 Trident,现在又出现了 Flink 这种优秀的实时计算框架,那么这几种计算框架到底有什么区别呢?下面我们来详细分析一下,如下表所示。
| 产品 | 模型 | API | 保证次数 | 容错机制 | 状态管理 | 延时 | 吞吐量 |
|---|---|---|---|---|---|---|---|
| Storm | Native(数据进入立即处理) | 组合式(基础API) | At-least-once (至少一次) | Record ACK(ACK机制) | 无 | 低 | 低 |
| Trident | Micro-Batching(划分为小批 处理) | 组合式 | Exactly-once (仅一次) | Record ACK | 基于操作(每次操作有一个状态) | 中等 | 中等 |
| Spark Streaming | Micro-Batching | 声明式(提供封装后的高阶函数,如count函数) | Exactly-once | RDD CheckPoint(基于RDD做CheckPoint) | 基于DStream | 中等 | 高 |
| Flink | Native | 声明式 | Exactly-once | CheckPoint(Flink的一种快照) | 基于操作 | 低 | 高 |
在这里对这几种框架进行对比。
模型
Storm 和 Flink 是真正的一条一条处理数据;而 Trident(Storm 的封装框架)和 Spark Streaming 其实都是小批处理,一次处理一批数据(小批量)。API
Storm 和 Trident 都使用基础 API 进行开发,比如实现一个简单的 sum 求和操作;而 Spark Streaming 和 Flink 中都提供封装后的高阶函数,可以直接拿来使用,这样就比较方便了。保证次数
在数据处理方面,Storm 可以实现至少处理一次,但不能保证仅处理一次,这样就会导致数据重复处理问题,所以针对计数类的需求,可能会产生一些误差;Trident 通过事务可以保证对数据实现仅一次的处理,Spark Streaming 和 Flink 也是如此。容错机制
Storm 和 Trident 可以通过 ACK 机制实现数据的容错机制,而 Spark Streaming 和 Flink 可以通过 CheckPoint 机制实现容错机制。状态管理
Storm 中没有实现状态管理,Spark Streaming 实现了基于 DStream 的状态管理,而 Trident 和 Flink 实现了基于操作的状态管理。延时
表示数据处理的延时情况,因此 Storm 和 Flink 接收到一条数据就处理一条数据,其数据处理的延时性是很低的;而 Trident 和 Spark Streaming 都是小型批处理,它们数据处理的延时性相对会偏高。吞吐量
Storm 的吞吐量其实也不低,只是相对于其他几个框架而言较低;Trident 属于中等;而 Spark Streaming 和 Flink 的吞吐量是比较高的。官网中 Flink 和 Storm 的吞吐量对比如下图所示。
图3:Flink 和 Storm 的吞吐量对比
工作中如何选择实时计算框架
前面我们分析了 4 种实时计算框架,那么公司在实际操作时到底选择哪种技术框架呢?下面我们来分析一下。需要关注流数据是否需要进行状态管理,如果是,那么只能在 Trident、Spark Streaming 和 Flink 中选择一个。
需要考虑项目对 At-least-once(至少一次)或者 Exactly-once(仅一次)消息投递模式是否有特殊要求,如果必须要保证仅一次,也不能选择 Storm。
对于小型独立的项目,并且需要低延迟的场景,建议使用 Storm,这样比较简单。
如果你的项目已经使用了 Spark,并且秒级别的实时处理可以满足需求的话,建议使用 Spark Streaming。
要求消息投递语义为 Exactly-once;数据量较大,要求高吞吐低延迟;需要进行状态管理或窗口统计,这时建议使用 Flink。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算