MongoDB分布式集群架构(3种模式)
本教程前面的内容基本涵盖了 MongoDB 的基本知识,现在在单机环境下操作 MongoDB 已经不存在问题,但是单机环境只适合学习和开发测试,在实际的生产环境中,MongoDB 基本是以集群的方式工作的。集群的工作方式能够保证在生产遇到故障时及时恢复,保障应用程序正常地运行和数据的安全。
接下来我们重点介绍 MongoDB 的集群工作方式,以及在集群工作方式下,MongoDB 是如何使用分片和复制的机制来完成对数据的管理和恢复的。
本节我们从理论上讲解 MongoDB 分布式集群架构的三种模式,下节《将MongoDB部署到分布式集群(实操)》我们会使用三台机器实际部署 MongoDB,带着大家实践一把,光说不练假把式。
MongoDB 有三种集群部署模式,分别为主从复制(Master-Slaver)、副本集(Replica Set)和分片(Sharding)模式。
Sharding 模式追求的是高性能,而且是三种集群中最复杂的。在实际生产环境中,通常将 Replica Set 和 Sharding 两种技术结合使用。
主从复制是 MongoDB 中最简单的数据库同步备份的集群技术,其基本的设置方式是建立一个主节点(Primary)和一个或多个从节点(Secondary),如下图所示。
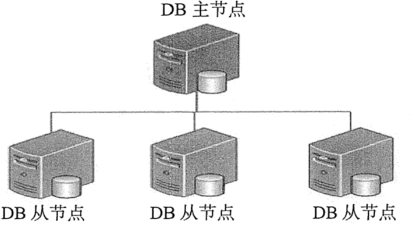
这种方式比单节点的可用性好很多,可用于备份、故障恢复、读扩展等。集群中的主从节点均运行 MongoDB 实例,完成数据的存储、查询与修改操作。
主从复制模式的集群中只能有一个主节点,主节点提供所有的增、删、查、改服务,从节点不提供任何服务,但是可以通过设置使从节点提供查询服务,这样可以减少主节点的压力。
另外,每个从节点要知道主节点的地址,主节点记录在其上的所有操作,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
在主从复制的集群中,当主节点出现故障时,只能人工介入,指定新的主节点,从节点不会自动升级为主节点。同时,在这段时间内,该集群架构只能处于只读状态。
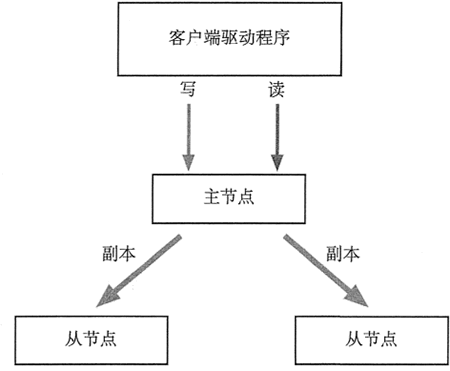
此集群拥有一个主节点和多个从节点,这一点与主从复制模式类似,且主从节点所负责的工作也类似,但是副本集与主从复制的区别在于:当集群中主节点发生故障时,副本集可以自动投票,选举出新的主节点,并引导其余的从节点连接新的主节点,而且这个过程对应用是透明的。
可以说,MongoDB 的副本集是自带故障转移功能的主从复制。
MongoDB 副本集使用的是 N 个 mongod 节点构建的具备自动容错功能、自动恢复功能的高可用方案。在副本集中,任何节点都可作为主节点,但为了维持数据一致性,只能有一个主节点。
主节点负责数据的写入和更新,并在更新数据的同时,将操作信息写入名为 oplog 的日志文件当中。主节点还负责指定其他节点为从节点,并设置从节点数据的可读性,从而让从节点来分担集群读取数据的压力。
另外,从节点会定时轮询读取 oplog 日志,根据日志内容同步更新自身的数据,保持与主节点一致。
在一些场景中,用户还可以使用副本集来扩展读性能,客户端有能力发送读写操作给不同的服务器,也可以在不同的数据中心获取不同的副本来扩展分布式应用的能力。
在副本集中还有一个额外的仲裁节点(不需要使用专用的硬件设备),负责在主节点发生故障时,参与选举新节点作为主节点。
副本集中的各节点会通过心跳信息来检测各自的健康状况,当主节点出现故障时,多个从节点会触发一次新的选举操作,并选举其中一个作为新的主节点。为了保证选举票数不同,副本集的节点数保持为奇数。
分片是指将数据拆分并分散存放在不同机器上的过程。有时也用分区来表示这个概念。将数据分散到不同的机器上,不需要功能强大的大型计算机就可以存储更多的数据,处理更大的负载。
MongoDB 支持自动分片,可以使数据库架构对应用程序不可见,简化系统管理。对应用程序而言,就如同始终在使用一个单机的 MongoDB 服务器一样。
MongoDB 的分片机制允许创建一个包含许多台机器的集群,将数据子集分散在集群中,每个分片维护着一个数据集合的子集。与副本集相比,使用集群架构可以使应用程序具有更强大的数据处理能力。
MongoDB 分片的集群模式如下图所示。
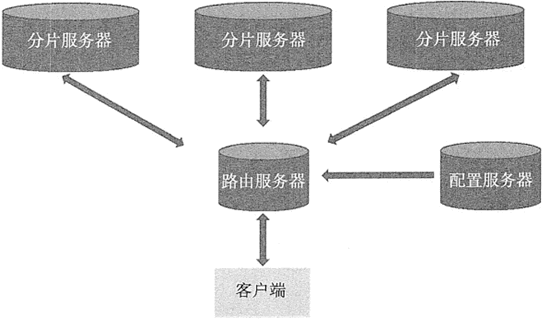 构建一个 MongoDB 的分片集群,需要三个重要的组件,分别是分片服务器(Shard Server)、配置服务器(Config Server)和路由服务器(Route Server)。
构建一个 MongoDB 的分片集群,需要三个重要的组件,分别是分片服务器(Shard Server)、配置服务器(Config Server)和路由服务器(Route Server)。
在实际生产中,一个 Shard Server 可由几台机器组成一个副本集来承担,防止因主节点单点故障导致整个系统崩溃。
Route Server 本身不保存数据,启动时从 Config Server 加载集群信息到缓存中,并将客户端的请求路由给每个 Shard Server,在各 Shard Server 返回结果后进行聚合并返回客户端。
以上介绍了 MongoDB 的三种集群模式,副本集已经替代了主从复制,通过备份保证集群的可靠性,分片机制为集群提供了可扩展性,以满足海量数据的存储和分析的需求。
在实际生产环境中,副本集和分片是结合起来使用的,可满足实际应用场景中高可用性和高可扩展性的需求。
接下来我们重点介绍 MongoDB 的集群工作方式,以及在集群工作方式下,MongoDB 是如何使用分片和复制的机制来完成对数据的管理和恢复的。
本节我们从理论上讲解 MongoDB 分布式集群架构的三种模式,下节《将MongoDB部署到分布式集群(实操)》我们会使用三台机器实际部署 MongoDB,带着大家实践一把,光说不练假把式。
MongoDB 有三种集群部署模式,分别为主从复制(Master-Slaver)、副本集(Replica Set)和分片(Sharding)模式。
- Master-Slaver 是一种主从副本的模式,目前已经不推荐使用。
- Replica Set 模式取代了 Master-Slaver 模式,是一种互为主从的关系。Replica Set 将数据复制多份保存,不同服务器保存同一份数据,在出现故障时自动切换,实现故障转移,在实际生产中非常实用。
- Sharding 模式适合处理大量数据,它将数据分开存储,不同服务器保存不同的数据,所有服务器数据的总和即为整个数据集。
Sharding 模式追求的是高性能,而且是三种集群中最复杂的。在实际生产环境中,通常将 Replica Set 和 Sharding 两种技术结合使用。
主从复制
虽然 MongoDB 官方建议用副本集替代主从复制,但是本节还是从主从复制入手,让大家了解 MongoDB 的复制机制。主从复制是 MongoDB 中最简单的数据库同步备份的集群技术,其基本的设置方式是建立一个主节点(Primary)和一个或多个从节点(Secondary),如下图所示。
这种方式比单节点的可用性好很多,可用于备份、故障恢复、读扩展等。集群中的主从节点均运行 MongoDB 实例,完成数据的存储、查询与修改操作。
主从复制模式的集群中只能有一个主节点,主节点提供所有的增、删、查、改服务,从节点不提供任何服务,但是可以通过设置使从节点提供查询服务,这样可以减少主节点的压力。
另外,每个从节点要知道主节点的地址,主节点记录在其上的所有操作,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
在主从复制的集群中,当主节点出现故障时,只能人工介入,指定新的主节点,从节点不会自动升级为主节点。同时,在这段时间内,该集群架构只能处于只读状态。
副本集
副本集的集群架构如下图所示。此集群拥有一个主节点和多个从节点,这一点与主从复制模式类似,且主从节点所负责的工作也类似,但是副本集与主从复制的区别在于:当集群中主节点发生故障时,副本集可以自动投票,选举出新的主节点,并引导其余的从节点连接新的主节点,而且这个过程对应用是透明的。
可以说,MongoDB 的副本集是自带故障转移功能的主从复制。
MongoDB 副本集使用的是 N 个 mongod 节点构建的具备自动容错功能、自动恢复功能的高可用方案。在副本集中,任何节点都可作为主节点,但为了维持数据一致性,只能有一个主节点。
主节点负责数据的写入和更新,并在更新数据的同时,将操作信息写入名为 oplog 的日志文件当中。主节点还负责指定其他节点为从节点,并设置从节点数据的可读性,从而让从节点来分担集群读取数据的压力。
另外,从节点会定时轮询读取 oplog 日志,根据日志内容同步更新自身的数据,保持与主节点一致。
在一些场景中,用户还可以使用副本集来扩展读性能,客户端有能力发送读写操作给不同的服务器,也可以在不同的数据中心获取不同的副本来扩展分布式应用的能力。
在副本集中还有一个额外的仲裁节点(不需要使用专用的硬件设备),负责在主节点发生故障时,参与选举新节点作为主节点。
副本集中的各节点会通过心跳信息来检测各自的健康状况,当主节点出现故障时,多个从节点会触发一次新的选举操作,并选举其中一个作为新的主节点。为了保证选举票数不同,副本集的节点数保持为奇数。
分片
副本集可以解决主节点发生故障导致数据丢失或不可用的问题,但遇到需要存储海量数据的情况时,副本集机制就束手无策了。副本集中的一台机器可能不足以存储数据,或者说集群不足以提供可接受的读写吞吐量。这就需要用到 MongoDB 的分片(Sharding)技术,这也是 MongoDB 的另外一种集群部署模式。分片是指将数据拆分并分散存放在不同机器上的过程。有时也用分区来表示这个概念。将数据分散到不同的机器上,不需要功能强大的大型计算机就可以存储更多的数据,处理更大的负载。
MongoDB 支持自动分片,可以使数据库架构对应用程序不可见,简化系统管理。对应用程序而言,就如同始终在使用一个单机的 MongoDB 服务器一样。
MongoDB 的分片机制允许创建一个包含许多台机器的集群,将数据子集分散在集群中,每个分片维护着一个数据集合的子集。与副本集相比,使用集群架构可以使应用程序具有更强大的数据处理能力。
MongoDB 分片的集群模式如下图所示。
Shard Server
每个 Shard Server 都是一个 mongod 数据库实例,用于存储实际的数据块。整个数据库集合分成多个块存储在不同的 Shard Server 中。在实际生产中,一个 Shard Server 可由几台机器组成一个副本集来承担,防止因主节点单点故障导致整个系统崩溃。
Config Server
这是独立的一个 mongod 进程,保存集群和分片的元数据,在集群启动最开始时建立,保存各个分片包含数据的信息。Route Server
这是独立的一个 mongos 进程,Route Server 在集群中可作为路由使用,客户端由此接入,让整个集群看起来像是一个单一的数据库,提供客户端应用程序和分片集群之间的接口。Route Server 本身不保存数据,启动时从 Config Server 加载集群信息到缓存中,并将客户端的请求路由给每个 Shard Server,在各 Shard Server 返回结果后进行聚合并返回客户端。
以上介绍了 MongoDB 的三种集群模式,副本集已经替代了主从复制,通过备份保证集群的可靠性,分片机制为集群提供了可扩展性,以满足海量数据的存储和分析的需求。
在实际生产环境中,副本集和分片是结合起来使用的,可满足实际应用场景中高可用性和高可扩展性的需求。
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算