C++ upper_bound(STL upper_bound)二分查找算法详解
二分查找一般比顺序搜索要快,但要求序列中的元素是有序的。这主要是因为二分查找的搜索机制,图 1 说明了这种机制。
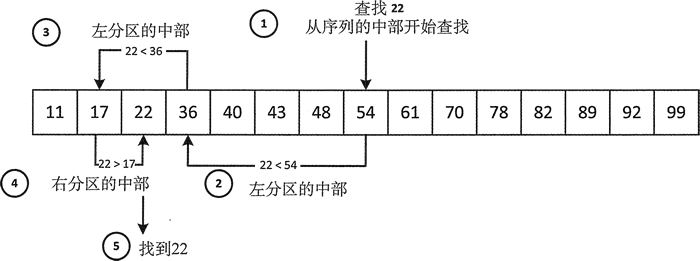
图 1 二分查找
图 1 展示了在一个升序序列中二分查找 22 的过程。因为元素是升序排列的,所以查找机制使用小于运算符来查找元素。搜索降序序列需要使用小于运算符来比较元素。二分查找总是选择从序列中部的元素开始,并将它和搜索的值作比较。如果元素和被查找的元素相等,就认为是匹配的,所以当 !(x<n)&&!(n<x) 时,n 的值也就匹配 x 的值。
如果检查的元素不匹配,比如 x<n,会继续从左分区的中间元素开始查找,否则继续从右分区的中间元素开始查找。当找到相等的元素或所检查的分区只有一个元素时,查找结束。此时如果不匹配,就说明元素不在这个序列中。
图 1 二分查找
图 1 展示了在一个升序序列中二分查找 22 的过程。因为元素是升序排列的,所以查找机制使用小于运算符来查找元素。搜索降序序列需要使用小于运算符来比较元素。二分查找总是选择从序列中部的元素开始,并将它和搜索的值作比较。如果元素和被查找的元素相等,就认为是匹配的,所以当 !(x<n)&&!(n<x) 时,n 的值也就匹配 x 的值。
如果检查的元素不匹配,比如 x<n,会继续从左分区的中间元素开始查找,否则继续从右分区的中间元素开始查找。当找到相等的元素或所检查的分区只有一个元素时,查找结束。此时如果不匹配,就说明元素不在这个序列中。
upper_bound()
upper_bound() 算法会在前两个参数定义的范围内查找大于第三个参数的第一个元素。对于这两个算法,它们所查找的序列都必须是有序的,而且它们被假定是使用 < 运算符来排序的。例如:
std::list<int> values {17, 11, 40, 36, 22, 54, 48, 70, 61, 82, 78, 89, 99, 92, 43};
values.sort (); // Sort into ascending sequence
int wanted {22}; // What we are looking for
std::cout<<"The upper bound for " << wanted<< " is " << *std::upper_bound (std::begin (values), std:: end (values), wanted)<< std::endl;
输出结果为:
The upper bound for 22 is 36
从 list 容器的整数中可以看出算法正像我们所描述的那样工作。该算法还有额外 的版本,它接受一个函数对象作为第三个参数,用于指定序列排序所使用的比较。所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算