汇编语言寄存器参数的缺点
多年以来,Microsoft 在 32 位程序中包含了一种参数传递规则,称为 fastcall。如同这个名字所暗示的,只需简单地在调用子程序之前把参数送入寄存器,就可以将运行效率提高一些。相反,如果把参数压入堆栈,则执行速度就要更慢一点。
典型用于参数的寄存器包括 EAX、EBX、ECX 和 EDX,少数情况下,还会使用 EDI 和 ESI。可惜的是,这些寄存器在用于存放数据的同时,还用于存放循环计数值以及参与计算的操作数。
因此,在过程调用之前,任何存放参数的寄存器须首先入栈,然后向其分配过程参数,在过程返回后再恢复其原始值。例如,如下代码从 Irvine32 链接库中调用了 DumpMem:
例如,在下面的代码中,第 8 行的 EAX 如果等于 1,那么过程在第 17 行就无法返回其调用者,原因就是有三个寄存器的值留在运行时堆栈里。
堆栈参数提供了一种不同于寄存器参数的灵活方法:只需要在调用子程序之前,将参数压入堆栈即可。比如,如果 DumpMem 使用了堆栈参数,就可以通过如下代码对其进行调用:
用 C++ 编写相同的功能调用则为
在 C/C++ 中,同样的函数调用将传递 val1 和 val2 参数的地址:
不愿意用值来传递数组的原因是显而易见的,因为这样就会要求将每个数组元素分别压入堆栈。这种操作不仅速度很慢,而且会耗尽宝贵的堆栈空间。
下面的语句用正确的方法向子程序 ArrayFill 传递了数组的偏移量:
典型用于参数的寄存器包括 EAX、EBX、ECX 和 EDX,少数情况下,还会使用 EDI 和 ESI。可惜的是,这些寄存器在用于存放数据的同时,还用于存放循环计数值以及参与计算的操作数。
因此,在过程调用之前,任何存放参数的寄存器须首先入栈,然后向其分配过程参数,在过程返回后再恢复其原始值。例如,如下代码从 Irvine32 链接库中调用了 DumpMem:
push ebx ;保存寄存器值 push ecx push esi mov esi,OFFSET array ;初始 OFFSET mov ecx,LENGTHOF array ;大小,按元素个数计 mov ebx, TYPE array ;双字格式 call DumpMem ;显示内存 pop esi ;恢复寄存器值 pop ecx pop ebx这些额外的入栈和出栈操作不仅会让代码混乱,还有可能消除性能优势,而这些优势正是通过使用寄存器参数所期望获得的!此外,程序员还要非常仔细地将 PUSH 与相应的 POP 进行匹配,即使代码存在着多个执行路径。
例如,在下面的代码中,第 8 行的 EAX 如果等于 1,那么过程在第 17 行就无法返回其调用者,原因就是有三个寄存器的值留在运行时堆栈里。
push ebx ;保存寄存器值 push ecx push esi mov esi, OFFSET array ;初始 OFFSET mov ecx, LENGTHOF array ;大小,按元素个数计 mov ebx, TYPE array ;双字格式 call DumpMem ;显示内存 cmp eax, 1 ;设置错误标志? je error_exit ;设置标志后退出 pop esi ;恢复寄存器值 pop ecx pop ebx ret error_exit: mov edx, offset error_msg ret不得不说,像这样的错误是不容易发现的,除非是花了相当多的时间来检查代码。
堆栈参数提供了一种不同于寄存器参数的灵活方法:只需要在调用子程序之前,将参数压入堆栈即可。比如,如果 DumpMem 使用了堆栈参数,就可以通过如下代码对其进行调用:
push TYPE array push LENGTHOF array push OFFSET array call DumpMem子程序调用时,有两种常见类型的参数会入栈:
- 值参数(变量和常量的值)
- 引用参数(变量的地址)
值传递
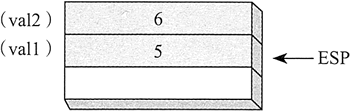
当一个参数通过数值传递时,该值的副本会被压入堆栈。假设调用一个名为 AddTwo 的子程序,向其传递两个 32 位整数:.data val1 DWORD 5 val2 DWORD 6 .code push val2 push val1 call AddTwo执行 CALL 指令前,堆栈如下图所示:
用 C++ 编写相同的功能调用则为
int sum = AddTwo(val1, val2);
观察发现参数入栈的顺序是相反的,这是 C 和 C++ 语言的规范。引用传递
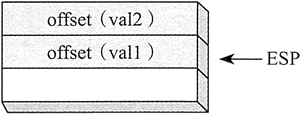
通过引用来传递的参数包含的是对象的地址(偏移量)。下面的语句调用了 Swap,并传递了两个引用参数:
push OFFSET val2
push OFFSET val1
call Swap
在 C/C++ 中,同样的函数调用将传递 val1 和 val2 参数的地址:
Swap(&vail, &val2);
传递数组
高级语言总是通过引用向子程序传递数组。也就是说,它们把数组的地址压入堆栈。然后,子程序从堆栈获得该地址,并用其访问数组。不愿意用值来传递数组的原因是显而易见的,因为这样就会要求将每个数组元素分别压入堆栈。这种操作不仅速度很慢,而且会耗尽宝贵的堆栈空间。
下面的语句用正确的方法向子程序 ArrayFill 传递了数组的偏移量:
.data array DWORD 50 DUP(?) .code push OFFSET array call ArrayFill
所有教程
- C语言入门
- C语言编译器
- C语言项目案例
- 数据结构
- C++
- STL
- C++11
- socket
- GCC
- GDB
- Makefile
- OpenCV
- Qt教程
- Unity 3D
- UE4
- 游戏引擎
- Python
- Python并发编程
- TensorFlow
- Django
- NumPy
- Linux
- Shell
- Java教程
- 设计模式
- Java Swing
- Servlet
- JSP教程
- Struts2
- Maven
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- Hibernate
- Mybatis
- MySQL教程
- MySQL函数
- NoSQL
- Redis
- MongoDB
- HBase
- Go语言
- C#
- MATLAB
- JavaScript
- Bootstrap
- HTML
- CSS教程
- PHP
- 汇编语言
- TCP/IP
- vi命令
- Android教程
- 区块链
- Docker
- 大数据
- 云计算